Topic Based Complaint Resolution on Automotive Manufacturing Data
In complex manufacturing processes, there are times when manufactured components do not adhere to the industry quality requirements. To account for and log the entire process of manufacturing of a product, different types of data are generated, including complaints regarding the quality of manufactured components. Until now, the process of logging complaints and taking follow-up actions, has entirely been manual in the manufacturing industry. This has led to long delays between issue resolution and inefficient manufacturing. Here, we propose an automated complaint resolution system, which analyzes a given complaint and recommends top three solutions, after being trained on historical complaints and follow-ups.
System Architecture
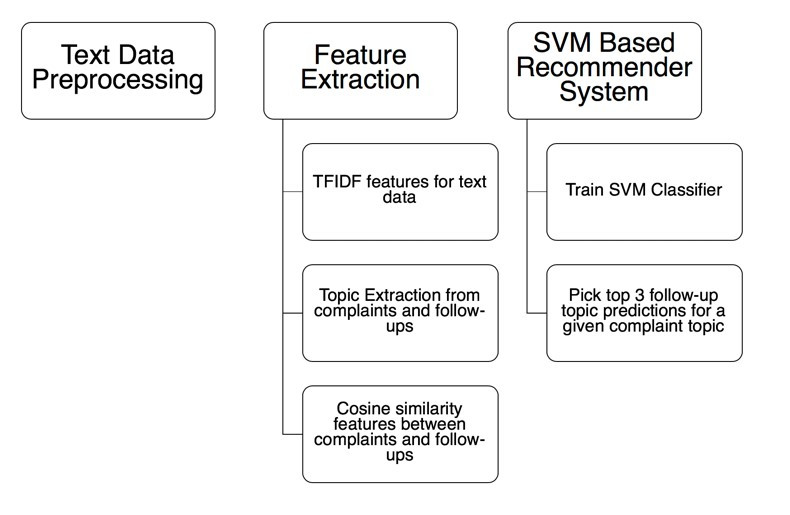
In order to build a complaint resolution system, which can infer natural language data, detect patterns between complaints and respective follow-ups and solutions and predict follow-up action themes, given a complaint theme, the system architecture is divided into three parts;
- Text data preprocessing
- Feature extraction from text data
- Multi-class classification to predict recommended solutions
The figure below depicts a visual representation of the system architecture, which has been utilized to create the recommender. The architecture follows a four-step flow as given below:
- Complaint is logged into the system by a plant operator.
- Complaint data is preprocessed to create a cleaner dataset.
- Complaint is analyzed and several features are extracted, including TFIDF, prevalent topic model theme and cosine similarity between complaints and follow-up features.
- A multi-class classifier, trained on historical data, outputs top three recommended solutions.
Text Data Preprocessing
The raw data being utilized to create this recommender model exists in the form of text data. This includes complaints, first follow-ups and second follow-ups, for every item for which a complaint was logged. The raw dataset consists of 1317 rows, collected during a period of ~21 months. On an average, 3 complaints are logged every day, on which follow-up actions are taken and logged, twice, namely follow-up 1 and follow-up 2. This text data cannot be used in its raw form to train a machine learning model, hence certain preprocessing steps need to be undertaken to create a more machine understandable representation of the natural language data.
Preprocessing of text data begins with the removal of special, numeric and new line characters from each complaint and follow-up. This is done to focus on certain action words which appear in each sentence. Each complaint and follow-up is tokenized and stop words are removed from respective tokens in order to reduce noise in input data, which will be utilized in several tasks further. Word tokens are also lemmatized in order to focus on their root meaning instead of treating two words with the same lemmas as two different words. Moreover, tokens are filtered to include only nouns, adjectives, verbs and adverbs, in order to focus on action words and identify different types of actions being taken to resolve certain complaints. Bi grams are then created from the word tokens to improve task accuracy and top modeling, which will be utilized in the feature engineering part of our model building framework. An example of preprocessed text can be seen in the figure given below.

Feature Engineering
Once text data is processed into keywords, several features need to be extracted from the data which can be fed into machine learning algorithms. These include the following:
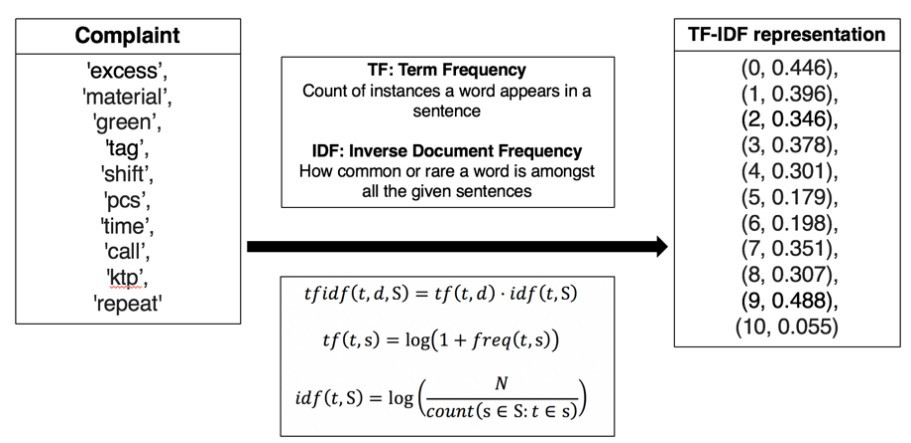
TFIDF Features
Each complaint comprises a group of multiple word tokens. These words are used to create a dictionary of words, which is used to create a bag-of-words model. This model is utilized to create TF-IDF representations of words, enabling efficient conversion of text data to numerical form. An example of TF-IDF features being generated is given in the figure below.
Topic Features
In order to identify different complaint and follow-up themes prevalent in the complaints dataset, a topic modeling approach is adopted. This is done by utilizing the TF-IDF features which were created in the previous step, which are used in a Latent Dirichlet Allocation (LDA) model [10] to identify key topics that can be identified and used to categorize a plethora of complaints and follow-ups into designated buckets. Here, the key aim is to group words in the given complaints and follow-ups into N topics and rate the likelihood of each word for each topic. Words are grouped based on the criteria that they frequently appear in the same sentences. Once grouped, words within each topic are reviewed and a general theme or topic is identified. Furthermore, in order to ensure maximum coherence of each topic, multiple topic models are built, with a varying number of topics, and each model’s coherence score is plotted. A coherence score measures the degree of semantic similarity between high-scoring words in each topic. The coherence scores for different topic models for complaints, first follow-ups (follow-up 1) and second follow-ups (follow-up 2) can be seen in the figure below.
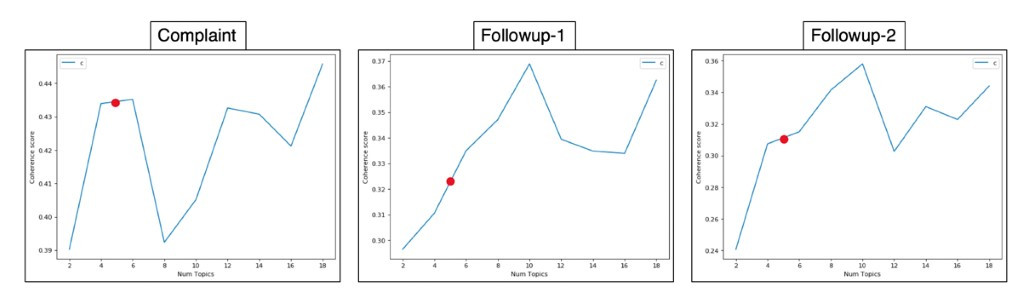
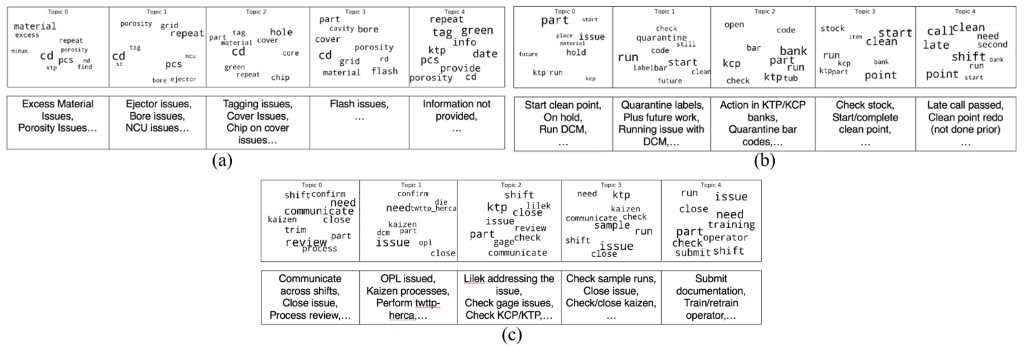
Here, we can see that high coherence is provided by topic models with a number of topics ~ 6 in case of complaints data, while for first and second follow-ups, topic models with the best coherence score are given when the number of topics ~10. In this work, we will be limiting our analysis to topic models with 5 topics each for complaints and follow-ups. This has been done to address the time and memory allocation issues and to create a primary framework for bench-marking of the entire recommender model. The topic models generated for complaints, first follow-ups, and second follow-ups can be seen in the figure below.
Cosine Similarity Features
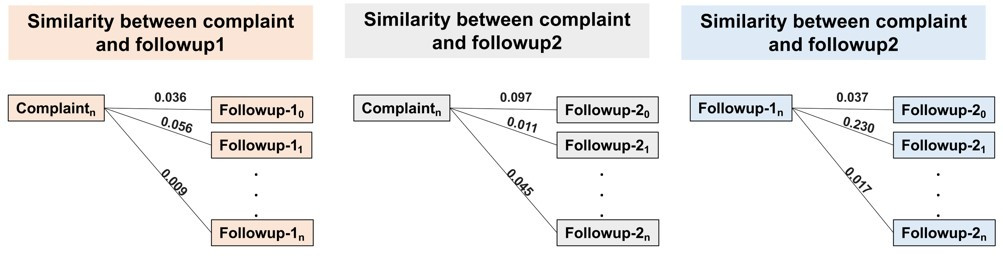
Once topic models have been built, another feature is computed to find the associations between each complaint and follow-up pair, by calculating the cosine similarity between TF-IDF vector representations of respective complaints and follow-ups. This is done in order to utilize the descriptive property of TFIDF vectors, without introducing the multidimensionality of given vectors. Hence, cosine similarity features provide a dense and informative parameter, which can be used as an input to a machine learning model. The figure below shows how cosine similarity features are calculated for each complaint and follow-up pair.
Classifier Based Recommender
Once features have been engineered, a multi-class classification algorithm is used to predict solution recommendations. This model takes the input topic model and cosine similarity features into account, to predict the top three solution topics and therefore solution themes.
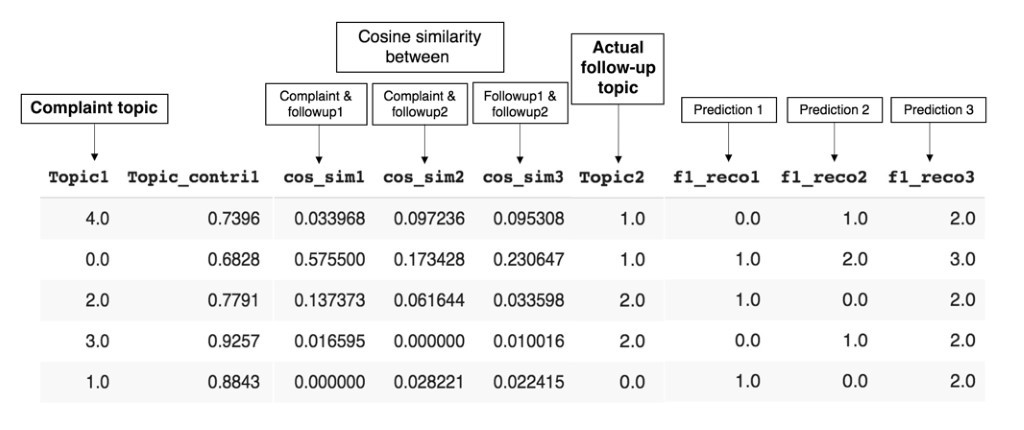
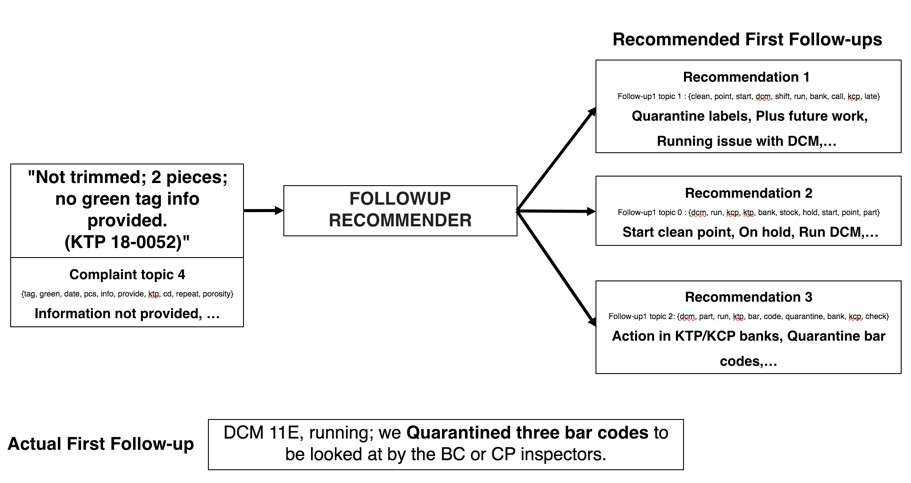
A multi-class classification approach has been chosen because the aim is to predict a follow-up topic among five follow-up topics, for a given complaint topic. In order to account for complexities in the given data, and for the model to learn and transform the data according to the kernel trick, an SVM classifier has been utilized. The classifier takes the complaint topic, complaint topic contribution score, cosine similarity between complaint and follow-up 1 pair, complaint and follow-up 2 pair and between follow-up 1 and follow-up 2 as inputs and learn to predict the follow-up 1 topic, as can be seen in the figure given below. By utilizing the probabilities, the classifier assigns to each follow-up topic for a given instance, a recommender system is built which picks the top three most probable follow-up topics, according to their predictive probability assigned by the classifier.
Here, two different types of SVM classifiers, a linear SVM classifier and a polynomial SVM classifier have been trained on the given data, using the features engineered in the previous step, including topic model and cosine similarity features. Their performances in terms of training and testing accuracy can be seen in Table 1 and Table 2 respectively.
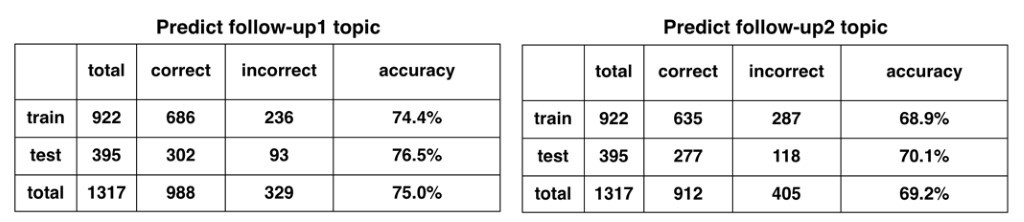
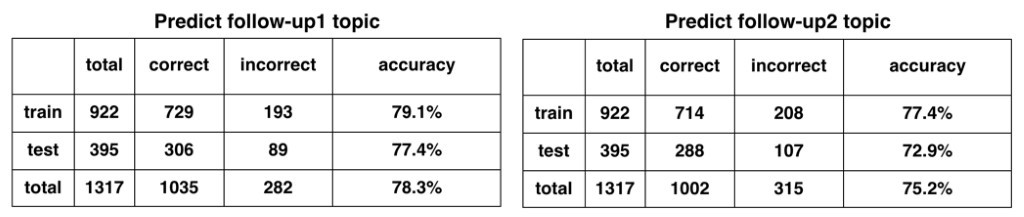
Here accuracy has been defined as getting the correct follow-up topic prediction within the top 3 ranked predictions, for a given complaint topic. The linear SVM classifier gives an accuracy of 76.5% and 70.1% on the test data, for follow-up 1 and follow-up 2 respectively. On the other hand, the polynomial SVM gives a better accuracy of 77.4% and 72.9%, for both follow-up 1 and follow-up 2. But a drawback of using a polynomial model is that it generally leads to overfitting of the model as can be seen in Table 2, where training accuracy is higher than testing accuracy. Moreover, there is only a slight improvement in accuracy as we shift from linear SVM to polynomial SVM, while getting an overfitted model. Thus, given these considerations, we finalize the linear SVM model to be used as the multi-class classifier in the recommendation model. An example of how the model predicts follow-ups is given in the figure below.
Conclusion and Future Work
This post describes a topic-based complaint resolution system, which utilizes topic modeling using Latent Dirichlet Allocation (LDA) and cosine similarity features to create a multi-class classifier, to create a recommender system that generates three suggested follow-ups for a given complaint. Without overfitting, the best performance on the test set is given by a linear SVM classifier-based recommender, with 76.5% and 70.1% accuracy in predicting follow-up 1 and follow-up 2. With overfitting, the best performance on the test set is given by a polynomial SVM classifier-based recommender, with 77.4% and 72.9% accuracy in predicting follow-up 1 and follow-up 2. As future work, topic modeling can be explored further where multi-topic assignments are also considered when creating a classification approach. Moreover, more data must be collected in order to create more robust models which account for more variation and noise during training.